
How to Get Started on Data Governance
This post describes the prerequisites as well as a methodology for a successful implementation of a data governance platform.

In this guest post, Syed Atif Akhtar provides insights on how an organization can get started on Data Governance. These insights are based on his experience helping organizations big & small to put data governance systems in place.
Data Governance helps organizations improve developer productivity, data quality, compliance, and security. However many organizations fail to extract value from data governance. This post describes the prerequisites as well as a methodology for a successful implementation of a data governance platform.
Prerequisites for a data governance implementation
Strategy and Vision
The strategy should clearly articulate the value proposition and goals of data governance. These should be articulated across different timelines. Goals and objectives help everyone see the value and maintain motivation to stick with the process.
The strategy has to consider both the tools as well as the organization. It is not sufficient to only introduce the right tools. Most organizations that follow a top-down driven approach often end up failing due to investing too much money on tools but do not consider the organization’s dynamics. Hence the right incentives have to be created for everyone in the organization to participate and take ownership of data governance within their area.
The strategy should support decentralization and adopt extensible tools. Each team should be able to add features they see fit and evolve the governance fabric itself based on the needs of the department.
The strategy should consider the needs of data engineers, data scientists, and AI engineers along with data analysts. Hence, a data governance strategy should include relational databases and data warehouses as well as technologies for data engineering, data science, and artificial intelligence. It should also consider that new technologies will become popular and will be adopted by the engineers in the team.
The strategy should push data governance in phases. The roadmap should consist of incremental improvements rather than overnight change to allow the organization to assimilate the new technologies and processes.
Comprehensive goals
The goal of data governance is typically limited to compliance, accountability, and audits. However, the value of data governance goes beyond compliance to developer productivity and data quality. Developer productivity and data quality provide higher levels of motivation to choose the right investments. For example, the organization will then own data governance instead of outsourcing it to a vendor. Sub-organizations will take ownership of datasets useful to them.
Technology
There are many factors to choosing the right data governance technologies. Some of them are:
Build vs Buy
Open Source vs Commercial
The right decision depends on the goals, vision, and capabilities of the team. For example, the organization may not be able to install and maintain an open-source project. In other cases, the project may not work with the ecosystem adopted by the enterprise.
Steps in a successful data governance implementation
Prototype Phase

The goal of the prototype phase is to answer these questions:
What are the datasets available?
Who is using the datasets?
How are the datasets used?
In the prototype phase:
Curate Important Data
Focus on a few teams. Ideally Data Science or AI teams.
Implement basic classification and tagging of data.
The catalog pulls metadata from storage systems. This is in contrast to push-based where data owners push metadata to a catalog. At this stage, pull-based is better because organizational buy-in to data governance is not yet there.
Enabling Phase

The goal of the scaling phase is to add tooling to analyze metadata and compliance.
In the enabling phase:
The organization moves to a push-based model.
Focus on reducing the friction to onboard new teams and datasets.
A central team creates compliance and audit policies.
The technology is augmented to analyze and implement these policies.
Automate reporting of compliance reports.
Scaling Phase:
In the final phase, the goal is to align teams on data domains and federate data governance.
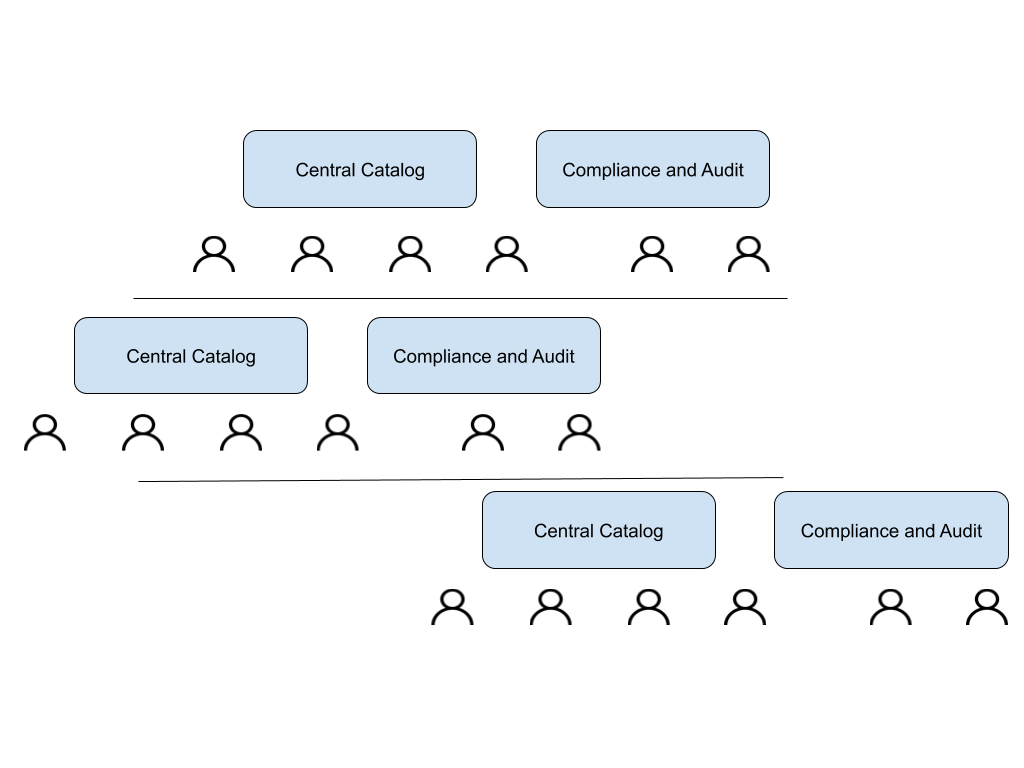
In the scaling phase:
Data Governance is decentralized. Data Stewards are part of sub-organizations.
Sub-organizations have the flexibility to choose their policies and managed through an Open Policy Agent.
Distributed data catalogs may be chosen to reflect the architecture of different data marts.
A business glossary is created to link code, SQL scripts, models, and transformations across different sub-organizations and data catalogs.
Conclusion
This post provides a blueprint for organizations to successfully implement data governance and extract value from it. Organizations should focus on strategy, goals, and technology. Then these should be implemented in phases by targeting simple goals first.